Dans ce tutorial, nous allons utiliser Linux-Perf pour collecter les données de performance d’une application parallèle. Notre but ici et de permettre simplement l’identification des points chauds d’un code donné, le tout en étant agnostique au runtime sous-jacent.
À la fin de ce module vous saurez:
- Collecter des données de performance avec Linux-perf
- Analyser ces données avec « perf report »
- Visualiser ces données avec « flamegraph »
Prè-requis
Linux-Perf repose sur des fonctionnalités noyau. Il est donc possible qu’il ne soit pas disponible dans certains environnements si vous n’êtes pas l’administrateur du système. De plus, certains admins sont réticents relativement à son installation car certaines autorisations sont requises pour permetre à perf de fonctionner.
En particuler la valeur du fichier /proc/sys/kernel/perf_event_paranoid est déterminante dans votre capacité à utliser perf. Si vous n’êtes pas root sur votre système, commencez par vérifier cette valeur. Si elle est de 2, il est possible que vous ne puissiez pas utiliser Perf, même si la commande est disponible.
La signification des valeurs et la suivante:
- -1 : Permettre l’utilisation de tous les évènements par tous les utlilisateurs
- >=0 : Interdire les « raw tracepoints » sans la capatité CAP_IOC_LOCK
- >=1 : Interdire la lecture des évènements CPU sans la capacité CAP_SYS_ADMIN
- >=2 : Interdire le profiling noyau aux utilisateurs sans la capacité CAP_SYS_ADMIN
Certains systèmes sont récicents à permettre l’utilisation de perf du fait de certaines failles par exemple (CVE-2013-2094), il peut donc il y avoir des objections à la mise en place de cette option sur des systèmes partagés.
Si vous êtes root sur vote machine, tout est plus simple car vous pourrez faire varier cette valeur en fonction de vos besoins de profilage.
Pour lire la valeur:
cat /proc/sys/kernel/perf_event_paranoid
Et naturellement pour définir cette valeur (en root uniquement):
echo "1" > /proc/sys/kernel/perf_event_paranoid
Installation
Sous Centos 7, il est possible d’installer perf en faisant:
sudo yum install perf gawk
Sous Ubuntu:
sudo apt install linux-tools-common gawk
Pour tester votre installation vous pouvez simplement faire la commande suivante:
perf record ls
Cela devrait produire une sortie proche de celle-ci:
perf.data
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.013 MB perf.data (21 samples) ]
Collecte de données
Nous allons maitenant faire notre première mesure avec linux Perf. Cet outil est très avancé et permet de faire du suivi à très faible grain. Vous êtes donc encouragés à aller plus loin que ce que nous allons efleurer dans ce tutoriel.
Nous commencerons par un programme trivial en C (test.c) :
#include <stdio.h>
int main(int argc, char **argv)
{
int i;
int j;
double result = 0.0;
for (i = 0; i < 100000; ++i)
{
for (j = 0; j < 10000; ++j) { result += i + j * 0,1; } } printf("--> %g\n", result );
return 0;
}
Compilons le code en mode débug :
gcc -g -O3 -o test ./test.c
Maintenant réalisons un profilage simple avec Perf:
perf record ./test
La sortie devrait être proche de la suivante, avec des informations relatives à Perf:
4.99995e+13
[ perf record: Woken up 2 times to write data ]
[ perf record: Captured and wrote 0.278 MB perf.data (6994 samples) ]
Exploration des données
La sortie la plus simple de Perf est obtenue sur la sortie standard avec :
perf report --stdio
Ce qui produit le profil suivant (reproduit ici partiellement):
# To display the perf.data header info, please use –header/–header-only options.
#
#
# Total Lost Samples: 0
#
# Samples: 6K of event ‘cycles:pp’
# Event count (approx.): 3018622192
#
# Overhead Command Shared Object Symbol
# …….. ……. …………….. ……………………………………
#
99.67% a.out a.out [.] main
0.09% a.out [kernel.kallsyms] [k] irq_return
0.04% a.out [kernel.kallsyms] [k] native_write_msr_safe
(…)
#
# (Tip: See assembly instructions with percentage: perf annotate )
#
On remarque surtout que 99,67 % du temps est passé dans la fonction main, mais d’où ces informations sont-elles venues ? observez dans le dossier courant, il ya un nouveau fichier « perf.dat », c’est ce fichier qui a permis la communication de « record » à « report ». Ce nom est le nom par défaut, raison pour laquelle nous n’avons pas eu à le spécifier. Il est possible de le modifier en utilisant respectivement « -o » dans record et « -i » dans report. À ce point nous vous encourageons à regarder l’aide de ces commandes de la manière suivante pour vérifier ces options:
perf report -h perf record -h
Perf permet également d’annoter le code source d’une fonction de manière simple, dans le dossier où vous avez effectué votre mesure, appeler la commande suivante:
perf annotate main --stdio
Notez que si vous omettez –stdio, vous aurez une version interactive du code source annoté. Cette commande produit alors la sortie désassemblée du code accompagnée du code source d’origine (car nous avons compilé avec -g). Nous pouvons alors dire exactement à quelle ligne le programme a passé la majeure partie de son temps (cf. capture d’écran).
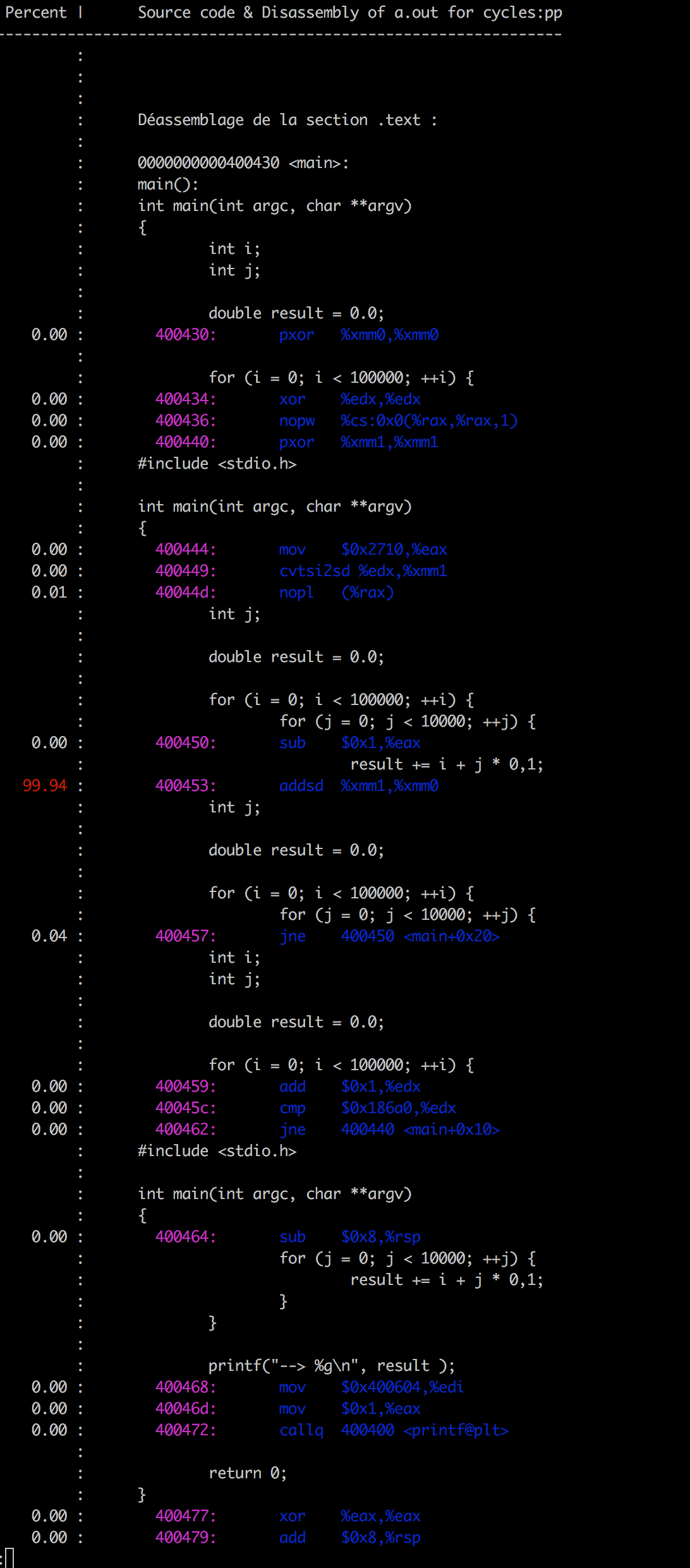
Il est possible d’appliquer cette commande à toute fonction qui contient des échantillons de mesure, ces fonctions sont listées par la commande « perf report ». De plus si vous la lançez sans l’option « –stdio » vous pourrez naviguer de manière interactive entre les fonctions mesurées. Il est également possible d’effectuer cette anotation depuis cette interface ncurses. Elle est donc plus pratique à l’usage bien que les sorties textuelles que nous avons exposées sont les plus utiles pour se concentrer sur une seule fonction d’intérêt.
Sorties Avancées
Il existe de nombreux modules permettant de post-traiter la sortie de Perf, nous alons ici nous concentrer sur l’un d’entre eux, le Flamegraph. C’est un outil complémentaire disponible sur Github http://www.brendangregg.com/flamegraphs.html. Encore une fois, nous n’exposerons pas toutes les possibilités de ce programme, nous vous invitons à vous référer à la documentation.
Installez tout d’abord flamegraph en clonant le dépôt GIT:
git clone https://github.com/brendangregg/FlameGraph.git
Ensuite rentrez dans le dossier et notez le chemin de l’installation:
cd FlameGraph pwd
Par exemple:
/home/jbbesnard/store/repo/FlameGraph
Nous feront par la suite référence à ce chemin en tant que FL_PREFIX.
Pour simplifier l’utilisation de l’outil nous allons devoir faire un petit script bash (il est entendu que vous adapterez la valeur de FL_PREFIX):
#!/bin/sh FL_PREFIX=/home/jbbesnard/store/repo/FlameGraph perf script $@ | $FL_PREFIX/stackcollapse-perf.pl | $FL_PREFIX/flamegraph.pl
Ce script appelle FlameGraph de la manière la plus simple possible et génère un fichier SVG sur la sortie standard. Il est possible de lui passer des options qui seront toutes passées à « perf script » (par exemple -i myprof.dat). Vous pouvez placer ce script dans votre PATH pour l’utiliser par la suite lors de vos mesures comme suit. Nous considérons que le script s’appelle flg.
Dans ce nouveau cas, nous allons intrumenter les piles d’appel, la commande de profilage devient donc:
perf record --call-graph fp ./test
Partons des données obtenue sur le benchmark Lulesh en contexte non OpenMP pour simplifier. Vous pouvez les télécharger ICI.
Nous allons maintenant générer la sortie de flamegraph en utilisant le script que nous avons créé dans l’étape précédente (veiller a correctement pointer vers la commande flg correspondant à votre script):
fgl > out.svg
Cela produit la sortie interactive suivante:
Utilisation en contexte MPI
Si vous souhaitez utiliser perf en contexte MPI, vous devez faire attention à générer des sorties différentes. En effet, si vous ne passez pas d’option, tous les processus MPI vont écrire dans le même fichier « perf.data ». Il faut donc créer un wrapper qui passera à « perf record » un nom différent pour chaque processus MPI. Par exemple le script suivant :
#!/bin/sh
H=`hostname`
P=$$
perf record -o perf-${H}-${P}.data $@
Le script s’utilise de la manière suivante (considérant que le wrapper est dans le PATH et qu’il s’appelle mpiperf):
mpirun -np 4 mpiperf ./program options
Avec ce script, de multiples fichiers perf-HOTE-PID.data seront générés dans le dossier courant, permettant d’instrumenter de multiples processus MPI.
Profilage à l’échelle du système
Parfois, il est intéressant de profiler un noeud dans sa totalité. Par exemple pour mesurer plusieurs applications à la fois. La commande est très simple mais requiert des droits suffisants pour l’utilisateur faisant la mesure.
La commande repose simplement sur l’option « -a » par exemple:
perf record -a --call-graph fp
Si la valeur de /proc/sys/kernel/perf_event_paranoid est incorrecte vous aurez ce message:
Error:
You may not have permission to collect system-wide stats.Consider tweaking /proc/sys/kernel/perf_event_paranoid,
which controls use of the performance events system by
unprivileged users (without CAP_SYS_ADMIN).The current value is 1:
-1: Allow use of (almost) all events by all users
>= 0: Disallow raw tracepoint access by users without CAP_IOC_LOCK
>= 1: Disallow CPU event access by users without CAP_SYS_ADMIN
>= 2: Disallow kernel profiling by users without CAP_SYS_ADMIN
La mise à -1 (en connaissance de cause) de ce fichier comme indiqué au début de ce tutoriel permettra de régler ce problème.
Surveillance Système
Il est également possible d’utiliser Perf pour afficher l’état « global » du système, évitant ainsi l’alternance, mesure puis affichage. La commande suivante permet d’afficher les fonctions consommant du temps CPU à l’instant t:
perf top
Conclusion
N’hésitez pas a nous faire vos retours sur cette introduction à Linux Perf. Notez qu’à ce point vous être très loin d’avoir utilisé toutes les fonctionnalités.